
引言
这两年我们见过太多企业,花几十万买的智能问数产品,最后只落得个"Demo"的下场。
厂商在会议室里演示得天花乱坠:你随便问,什么都能答。99.9%的SQL准确率,秒级返回结果,图表自动生成。
老板当场拍板:买!
结果上线即废。
业务部门:"Demo里问什么都对,一到真实业务就答非所问。"
数据部门:"同一个GMV,三个部门查出三个数,天天吵架,最后还是得我手动算。"
负责人:"它只会给一堆的数字,永远不会告诉我为什么会这样,更不会说接下来该怎么办。"
所有人都在骂大模型不行。说等GPT-5出来,等下一代模型能力再强一点,这些问题自然就解决了。
但Data Hunter见过上百个智能问数项目的生死,想说句真话:
智能问数不行,真的跟大模型没关系。
一、智能问数走的两条路,其实是死胡同
现在市面上所有的智能问数产品,都在拼一个数字:SQL生成准确率。
95%、98%、99.9%,数字越标越高,PPT越做越炫。好像只要这个数字做到100%,所有问题就都迎刃而解了。
但我想问一句:企业真的需要一个更会写SQL的机器吗?
你去问问任何一个业务人员,他们问数据的时候,想要的是什么?
不是一个字段,而是“这个月我卖了多少钱,跟上个月比是涨了还是跌了,为什么会这样,接下来我该怎么办”。
这些问题,没有一个是SQL能回答的。
一个写得完美无缺的SQL,如果用错了表、用错了口径,出来的就是垃圾数据。而垃圾数据,比没有数据还可怕,它会让你基于错误的结论做出错误的决策。
可整个行业都在假装看不见这个问题。大家都在比谁的翻译能力更强,却没人愿意停下来想一想:用户真正需要的,到底是什么?
正是对这个问题的不同回答,让行业分化出了两条主流路线。但遗憾的是,这两条路,从根上就走不通。
第一个坑:给旧BI打个"AI补丁",越补越烂
这是绝大多数传统BI厂商的选择。成本最低,见效最快。
原来的架构一点不动,只是给数据集加一层注释:这个字段叫什么,是什么意思,属于哪个主题。然后告诉大模型:“你照着这些注释去理解业务,然后写SQL就行。”
昨天还是个普通BI,今天贴个AI标签,价格就能翻三倍。 但它的致命缺陷,会在上线两个月后集中爆发。
我见过最夸张的一家制造企业,最开始只有10个数据集,维护起来轻轻松松。随着业务发展,数据集变成了100个、500个。每个数据集都有自己的规则和口径。
同一个“用户”,在用户表是“注册用户”,在订单表是“下单用户”。
同一个“销售额”,有的包含退款,有的不包含;
最后你会发现,维护这些静态注释的成本,比雇一整个数据团队还高。更可怕的是,当规则多到一定程度,连管理员自己都搞不清哪个是对的。
智能问数就这样变成了“猜数游戏”。用户问一个问题,系统随机返回一个结果,谁也不敢信,谁也不敢用。

第二条死路:建一个“完美”的语义层
为了解决口径不一致的问题,一些厂商提出了“语义层”的概念。听起来特别美好:我们提前把所有指标、维度、规则都统一建模,做成企业的“单一事实来源”。以后所有人都用同一套口径,再也不会吵架了。
现实呢?搭建一套完整的语义层需要多久?
3个月起步,半年是常态。你需要拉着销售、市场、运营、财务所有部门的人开会,一个指标一个指标地对齐定义,一条规则一条规则地梳理清楚,然后再由技术人员一条条写进系统里。
等你终于把所有指标都定义好了,抬头一看,业务早就变了。
618促销规则改了,新的业务线上线了,公司的组织架构调整了。你花了半年时间、几百万成本建的语义层,一夜之间就过时了。
有个客户跟我说,他们刚把语义层建完第二天,公司宣布拆分了两个事业部,所有的组织架构维度全废了。6个月的投入,直接打了水漂。
这种"先治理后使用"的模式,完全颠倒了主次。不是系统去适配业务,而是让业务去迁就系统。
这就是为什么很多企业花了几百万建语义层,最后业务部门还是宁愿用Excel自己算。

二、两条路的共同死穴:用静态业务去对抗动态业务
很多人没有意识到,这两条看似对立的路线,其实共享同一个底层逻辑:
用预先定义的静态语义,去覆盖无限可能的动态业务。
无论你是把语义写在数据集里,还是写在语义层里,它都是死的、固化的、提前想好的。但真实的业务是活的、变化的、永远超出你预设的。
你永远不可能提前定义好所有的业务问题。而企业最有价值的那些提问,恰恰是那些没人想到过的问题。
更致命的是,它们都依赖单一大模型来完成所有工作。
让一个大模型同时承担需求理解、口径对齐、取数计算、分析推理、报告生成的所有任务,就像让一个人同时做产品、开发、测试、运营、客服。 哪怕他再聪明,也必然顾此失彼。
这就是为什么哪怕SQL生成准确率做到100%,智能问数依然不好用。因为它解决的只是"怎么写SQL"的问题,而企业真正需要解决的,是"怎么理解业务、怎么分析数据、怎么给出可信结论"的问题。
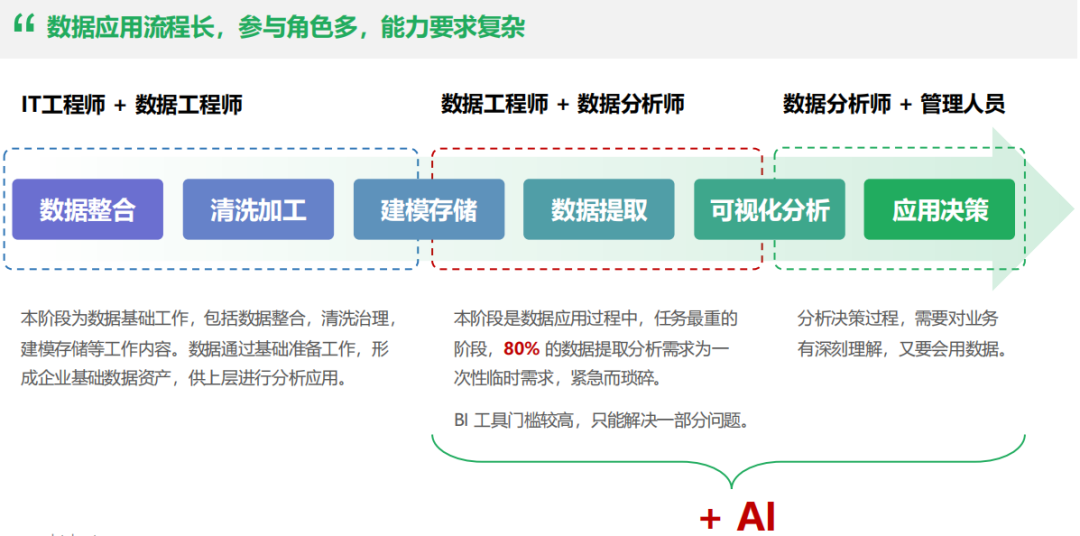
三、真正能落地的智能问数,核心是“复刻分析师团队”,而不是“写SQL”
很多人觉得,只要大模型足够强大,就能一个人搞定从理解问题、写SQL、取数、分析到给出结论的全部工作。
但这就像让一个刚毕业的大学生,同时兼任需求分析师、数据工程师、数据分析师和业务顾问。 他可能SQL写得很好,但他不懂你们公司的业务黑话。
他可能懂一点业务,但他不知道哪张表的数据是准的,哪个指标有坑。
他可能知道数据的坑,但他不知道怎么结合业务场景给出有价值的建议。
这不是能力问题,是分工问题。
一个优秀数据团队,从来都不是一个人单打独斗,而是一个分工明确、高效协作的团队。
- 有人负责跟业务沟通需求,把模糊的问题变清晰;
- 有人负责对齐指标口径,确保所有人说的是同一个东西;
- 有人负责写SQL取数,保证数据准确;
- 有人负责做根因分析,找到问题的本质;
- 有人负责写报告,把复杂的数据变成可执行的决策建议。
大家各司其职,互相校验,互相补位,才能最终输出一个业务敢信、能用、能落地的分析结果。
回到原来的问题:智能问数的终局是什么?
不是一个能写所有SQL的大模型,而是能完美复刻一个专业数据分析团队的工作流。
多Agent的智能问数,是给每个环节,都配一个专业的智能体,让它们像真实的团队一样,分工协作,闭环完成整个分析任务。
这不是技术概念的堆砌,而是智能问数唯一能从Demo走向落地的正确路径。
这也是我们DataHuter基于十年企业数据服务经验,打磨出的可落地的解决方案。我们打造的Data Neo数据分析决策智能体,彻底抛弃了"单一大模型做翻译"的老路,用Multi-Agent多智能体架构,完整复刻了一个专业数据分析团队的全流程工作。
1.意图澄清Agent:先懂你,再做事
它就像你们公司那个最懂业务的需求对接人。 当你问"上个月的销售额怎么样"的时候,它不会直接给你一个数,而是会主动问你:
"请问你指的是全渠道还是线上渠道?
是含税还是不含税
是确认收入还是订单金额?"
没有一句废话,只把模糊的业务问题,收敛成无歧义的分析任务。从根源上杜绝"答非所问"。
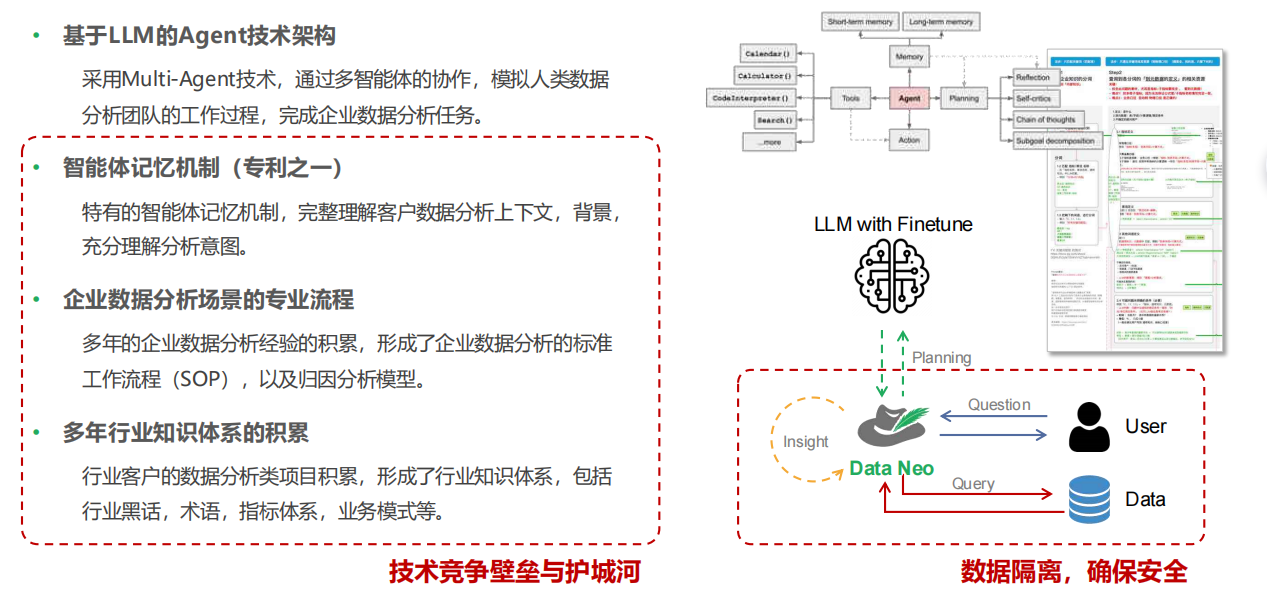
2.语义治理Agent:边用边治理,打破死局
针对语义层"覆盖窄了不够用,覆盖宽了做不起"的行业死局,Data Neo用语义治理Agent给出了完美解法。
它会自动学习企业的指标体系、口径规则、业务术语,自动完成字段映射、实体对齐、口径统一。不用人工一条条写死规则,更不用投入巨大的成本做一次性的语义层建设。
系统越用越懂业务,所有的分析过程都会自动沉淀到语义体系里,形成正向循环。
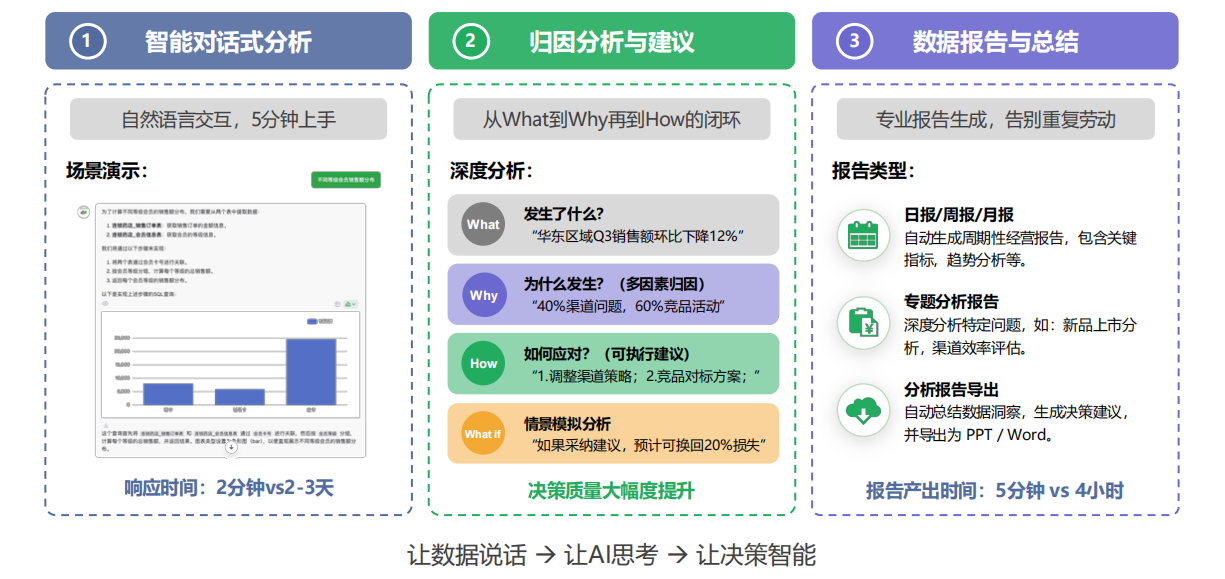
3.根因分析+决策建议Agent:从"返回数据"到"输出洞察"
传统智能问数的终点是"返回数据和图表",而Data Neo的起点是"分析数据"。 当你问"为什么5月的GMV同比下降了15%",Data Neo不会只给你一个下降的数字。它会自动启动多Agent协同分析,最终你得到的,不是一堆看不懂的表格,而是这样清晰的结论
四、最后想说
大家被 “一句话取数” 的美好愿景吸引,一头扎进去,最后却困在 Demo 里,走不进真实的业务场景。然后把失败归因为模型不够强,等着下一代大模型来拯救。
但其实,能拯救智能问数的,从来不是更强的翻译能力,而是对企业数据分析本质的理解。
企业需要的,从来不是一个会写SQL的机器,而是一个能懂业务、能控风险、能给结论、能帮决策的智能伙伴。
而这条路,只有多Agent协作能走通。